
OpenAI Unveils Cutting-Edge Speech Models for Enhanced Transcription and Voice Generation
OpenAI, a trailblazer in artificial intelligence research, has recently unveiled its latest speech-to-text and text-to-speech models through its API. This development marks a significant leap forward in the realm of transcription accuracy and voice generation control. By prioritizing these aspects, OpenAI is poised to revolutionize automated speech applications for a myriad of industries and applications.
Enhanced Transcription Accuracy
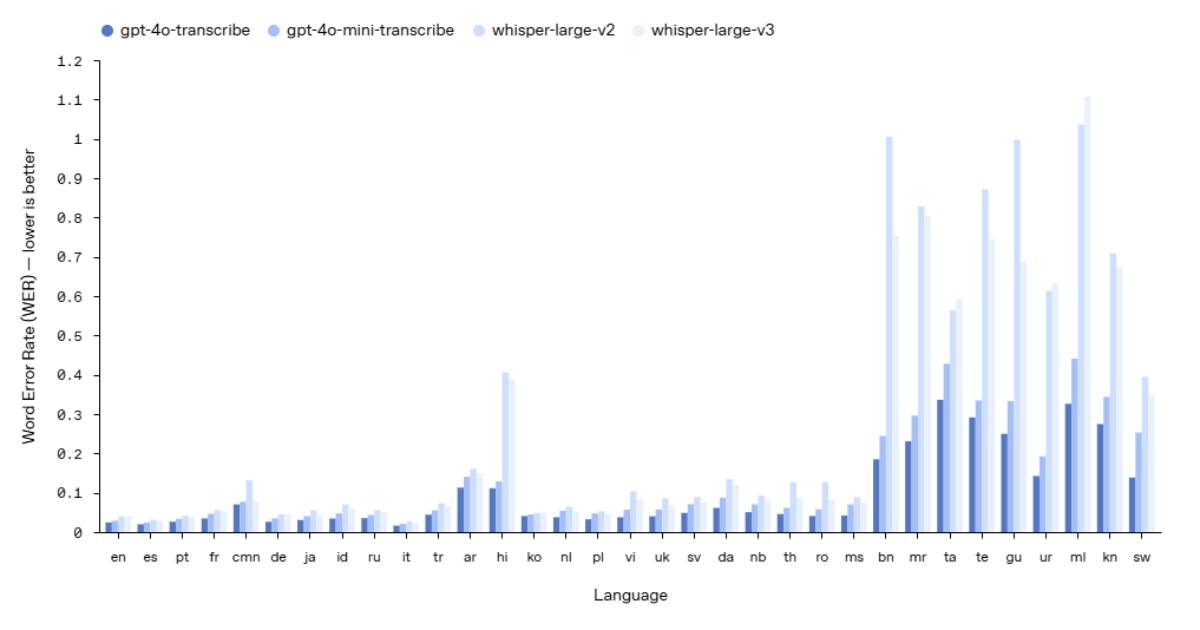
One of the key highlights of OpenAI’s new speech models is their unparalleled transcription accuracy. By leveraging advanced machine learning algorithms and neural networks, these models excel in converting spoken language into text with remarkable precision. This breakthrough is a game-changer for industries reliant on transcription services, such as healthcare, legal, and media, where accuracy is paramount.
In practical terms, imagine a medical professional dictating patient notes with complex terminology. With OpenAI’s enhanced speech-to-text model, every nuanced detail is transcribed flawlessly, reducing the margin of error and streamlining documentation processes. This level of accuracy not only boosts efficiency but also enhances data integrity and accessibility.
Empowering Voice Generation Control
Moreover, OpenAI’s updated text-to-speech models offer users unprecedented control over AI-generated voices. This newfound flexibility enables developers and businesses to tailor voice characteristics, such as pitch, tone, and cadence, to align with specific branding or communication requirements. By customizing these elements, organizations can create more engaging and personalized experiences for their target audience.
For instance, a customer service chatbot powered by OpenAI’s text-to-speech model can now deliver responses in a voice that resonates with the brand’s identity, fostering stronger customer connections. This level of voice customization not only elevates user engagement but also reinforces brand consistency across various touchpoints.
Adaptable Solutions for Diverse Use Cases
OpenAI’s commitment to enhancing automated speech applications extends to ensuring adaptability across diverse environments and use cases. Whether it’s transcribing multilingual conversations in real-time or generating lifelike voices for virtual assistants, these new models offer unparalleled versatility and performance.
By catering to a wide range of industries, including education, entertainment, and accessibility, OpenAI’s speech models unlock a wealth of possibilities for innovation and efficiency. Imagine a language learning app that provides real-time translations with utmost accuracy or a podcast platform that seamlessly generates natural-sounding voices to captivate listeners. With OpenAI’s cutting-edge solutions, the potential for transformative applications is limitless.
In conclusion, OpenAI’s latest speech models represent a significant advancement in the field of automated speech technology. By prioritizing transcription accuracy, voice generation control, and adaptability, these models pave the way for enhanced user experiences, streamlined workflows, and innovative applications across various industries. As organizations embrace these state-of-the-art solutions, the future of automated speech technology looks more promising than ever before.
With OpenAI leading the charge, the possibilities are endless, and the impact is bound to be profound.
Image Source: InfoQ
{kind=link}